「サマーインターン2011問題 : Preferred Research」について考えてみる
今更ながら,「サマーインターン2011問題 : Preferred Research」について考えたので,ここにメモ.
問題の概要を箇条書きにすると
- 長さ n の文字列 s が与えられる
- s に含まれる文字の中で,出現回数が最も大きい文字を出力せよ
- ただし,出現回数が最大の文字の出現回数は n/2 より大きい
- 計算時間は O(n) でなければならない
- 空間使用量は s を格納するバッファを除いて O(1) でなければならない
- s を格納するバッファは書き換えてよい
解法1
よく考えると,s をソートしたときに n/2 番目に来る要素は,出現回数が最大の文字であることがわかります.「ソートしたときに k 番目に来る要素」というのは,実際にソートをしなくても O(n) で求めることができ,問題の条件を満たします.C++ の標準ライブラリには nth_element という関数が用意されており,これを使うと簡単に「ソートしたときに k 番目に来る要素」を計算できます.
解法2
次のアルゴリズムを考えます.
for (;;) {
添字 i を [0, n) からランダムに選ぶ;
文字 s[i] の出現回数をリニアにカウントする;
if (s[i] の出現回数 > n/2) return s[i];
}
1回の反復で答えが求まる確率は少なくとも1/2あるので,平均計算時間は
(1 + 1/2 + 1/4 + ...) O(n) = O(n)
となり問題の条件を満たします.
[論文紹介] GConnect: A Connectivity Index for Massive Disk-Resident Graphs
授業で論文紹介したので,ここにメモ.
『GConnect: A Connectivity Index for Massive Disk-Resident Graphs』は,巨大なグラフに対してインデックスを作って,辺連結度クエリに高速に答える手法について議論した論文です.以下のような問題を考えます.
巨大なグラフGが与えられる.(例えば,頂点数10万,辺数100万とか)
G内の任意の2点s, tが与えられたとき,sとtの辺連結度を高速に計算せよ.
2頂点の辺連結度というのは,グラフから最小で何本辺を取り除けば,その2頂点を非連結にできるかで定義される量です.
計算時間を気にしなければ,最大 s-t フローを求めるアルゴリズム(Dinic や Goldberg-Tarjan など)で連結度を計算することができます.しかし,これらのアルゴリズムは記憶領域へのランダムアクセスを要求するため,メモリに格納できないサイズのグラフに対しては非常に遅くなり得ます.情報検索への応用を考えると,(s, t)が与えられたときに,数秒で答えを返さなければなりません.そこで,厳密解を求めることを諦め,近似解を求めることにし,事前に巨大なグラフをメモリに収まるサイズまで圧縮しておくことを考えます.
グラフの圧縮は,辺サンプリングに基づいて行います.下図(論文中の図から引用)のように,グラフ内の各辺に対して,一定の確率 f でその辺をサンプルします.そして,サンプルされた辺による連結成分を縮約します.結果として,頂点数と辺数が小さくなったグラフができます.
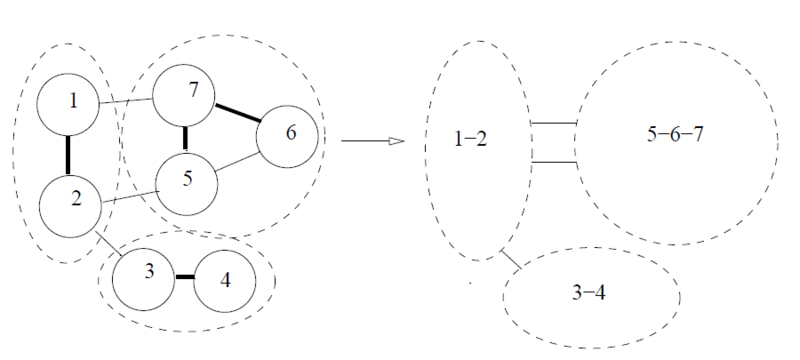
なぜこれで辺連結度の近似ができるのでしょうか?まず,辺連結度というのは,グラフの中の辺が比較的疎な部分で決まりやすいという性質を持っています.さらに,グラフの辺サンプリングは,辺が密な部分は,多くの辺がサンプルされ,一つの頂点に縮約されやすく,また,辺が疎な部分は,余り辺がサンプリングされず,縮約もされにくいという性質を持っています.よって,グラフの辺が疎な部分の構造が辺サンプリングによって保存されやすいため,辺連結度を概ね保存したまま,グラフを圧縮できるというわけです.
頂点対(s, t)に対応する,圧縮されたグラフの頂点対が(s', t')であったとします.ここで,s' ≠ t' とします.真のs-t辺連結度が C であるとすると,辺サンプリングによって正しくs-t辺連結度が求まる確率は少なくとも (1 - f)^C あります.(最小 s-t カットに含まれる辺がいずれも辺サンプリングによって選ばれない確率が (1 - f)^C です)
より高い確率で正しく辺連結度を求めるため,圧縮されたグラフを k 個作成し,それぞれの圧縮されたグラフで辺連結度を計算し,それらの最小値を答えとして返すことにします.(圧縮によって辺連結度が大きくなる場合は存在するが,逆の場合は存在しないので,最小値をとるのが良い)
圧縮されたグラフにおいて,s' = t' になってしまった場合は,辺連結度を計算できません.このような場合に対処するために,論文では,頂点サンプリングを使って圧縮したグラフを導入しています.詳しくは論文を読んでください.
現実のグラフを使った実験結果によると,圧縮によりグラフのサイズを 93% ~ 99% 程度減らすことができ,それによるエラーは6%以下にとどまっています.クエリの計算時間は,ナイーブな場合にくらべて 500倍程度速くなったようです.
[論文紹介] Fast shortest path distance estimation in large networks
とりあえず最近読んだ論文の紹介でも.
Webやソーシャルネットワークなど,巨大なグラフに対して,データマイニングや情報検索を行う際に,頂点間の最短距離を計算するという処理は,しばしば必要されますが,この規模のグラフに対して,BFSやDijkstra法を直接行うと時間がかかりすぎるという問題があります.『Fast shortest path distance estimation in large networks』は,頂点の小さなサブセットに対して,予め最短距離を求めておくことで,最短距離クエリに対して高速に答えを近似する手法について議論した論文です.アルゴリズムは大体以下のようになります.
- 上手く頂点のサブセットを選ぶ.ここで選ばれた頂点をランドマークと呼ぶことにする.
- グラフ内の任意の点vと,任意のランドマークuに対して,vからuへの最短距離を記録しておく.
- sからtへの最短距離クエリが与えられたとき,全てのランドマークuに対して,
(sからuへの最短距離) + (tからuへの最短距離)
を2で記録した値から計算し,その最小値を最短距離の近似値として返す.
このアルゴリズムでは,1のランドマークの選び方によって,近似の良さが変化します.(sからuへの最短距離) + (tからuへの最短距離) が,(sからtへの最短距離) に一致する必要十分条件は,uがsからtへの最短経路上にあることなので,ランドマークは,できるだけ最短経路に多く含まれている頂点を選べば良さそうだという直観を得ることができます.しかし,最良のランドマークを選ぶ問題はNP困難であることが証明できるので,ランドマークはヒューリスティックに選ぶことになります.論文では,ランドマークの選択に使うヒューリスティックをいくつか提案し,それらを比較していました.平均的に最も良い結果を与えるとされたヒューリスティックは closeness centrality の考え方に基づくものでした.
頂点vの closeness centrality は,その頂点からグラフ内の全ての頂点への最短距離の平均で定義されます.直感的に,小さい closeness centrality を持つ頂点は,多くの最短経路に含まれていると考えられるので,よいランドマークの候補になります.closeness centrality は,真面目に全頂点への最短距離を求めなくても,頂点のサンプリングをすることで精度良く近似できるらしいです.
実験では,closeness centrality が小さい順にランドマークを選んだ場合,ランダムに選んだ場合と比べて,同じ近似精度を1/250のランドマーク数で達成しています.辺数が7000万以上あるグラフに対して,数十個のランドマークで,真の最短距離との相対誤差が10%以下に抑えられており,結構上手く近似できているようです.