VirtualBoxにArch Linuxをインストールしたときのメモ
VirtualBoxにInstall media 2012.08.04 を使用してArch Linuxをインストールしたときのメモ.VMのディスクサイズは40GB,メモリは4GB.メモリサイズが1GB以上あるときはswap作らないほうがパフォーマンスがでるらしいのでswapなし.
いつの間にかインストーラが削除されていてArch Linuxのインストールが面倒になってました.
# loadkeys jp106 # parted (parted) unit MiB (parted) mklabel msdos (parted) mkpart primary 1 10241 (parted) mkpart primary 10241 20481 (parted) mkpart primary 20481 20581 (parted) mkpart extended 20581 40959 (parted) mkpart logical 20582 40959 (parted) quit # mkfs -t ext4 /dev/sda1 # mkfs -t reiserfs /dev/sda2 # mkfs -t ext2 /dev/sda3 # mkfs -t ext4 /dev/sda5 # mount -t ext4 /dev/sda1 /mnt # mkdir /mnt/{var,boot,home} # mount -t reiserfs /dev/sda2 /mnt/var # mount -t ext2 /dev/sda3 /mnt/boot # mount -t ext4 /dev/sda5 /mnt/home # vi /etc/pacman.d/mirrorlist 日本のサーバをリストの一番上に持ってくる # pacstrap /mnt base base-devel # pacstrap /mnt grub-bios # genfstab -p /mnt >> /mnt/etc/fstab # arch-chroot /mnt # vi /etc/hostname arch-vm # ln -s /usr/share/zoneinfo/Asia/Tokyo /etc/localtime # vi /etc/locale.conf LANG="en_US.UTF-8" LC_COLLATE="C" LC_TIME="en_DK.UTF-8" # vi /etc/locale.gen 以下の3行のコメントアウトを解除 en_DK.UTF-8 UTF-8 en_US.UTF-8 UTF-8 ja_JP.UTF-8 UTF-8 # locale-gen # mkinitcpio -p linux # mv /boot/grub /boot/grub-legacy # mkdir /backup # dd if=/dev/sda of=/backup/mbr-backup bs=512 count=1 # modprobe dm-mod # grub-install --target=i386-pc --recheck --debug /dev/sda # mkdir -p /boot/grub/locale # cp /usr/share/locale/en\@quot/LC_MESSAGES/grub.mo /boot/grub/locale/en.mo # grub-mkconfig -o /boot/grub/grub.cfg # vi /etc/rc.conf 次の行を追加 KEYMAP=jp106 # passwd rootパスワードを設定 # exit # umount /mnt/{var,boot,home,} # reboot
# pacman -S zsh vim tmux git openssh sudo # pacman -S virtualbox-archlinux-additions # modprobe -a vboxguest vboxsf vboxvideo # vim /etc/modules-load.d/vbox.conf vboxguest vboxsf vboxvideo # pacman -S dbus # vim /etc/rc.conf DAEMONSにdbusを加える # rc.d start dbus # pacman -S xorg # pacman -S gnome # pacman -S gdm # pacman -S xorg-xinit xterm # vim /etc/inittab id3:initdefault: をコメントアウトして id5:initdefault: のコメントアウトを解除 x:5:respawn:/usr/bin/xdm -nodaemon をコメントアウトして x:5:respawn:/usr/bin/gdm -nodaemon のコメントアウトを解除 # vim /etc/skel/.xinitrc VBoxClient-all & exec ck-launch-session gnome-session # adduser 普段使い用ユーザを追加 # visudo 今追加したユーザをsudoerにする
ノートPCのVirtualBox上にDebian環境を作る
やりたいこと
- ホストOSはWindows,ゲストOSはDebian,仮想化にはVirtualBoxを使用
- インターネットにはNATで接続
- DebianにはGUI環境をインストールせず,常にPuTTYを通じて使用する
- DebianのファイルをSambaを使ってWindowsと共有する
やったこと
- VMのネットワークの設定
インターネットにはNATで接続したいので,アダプタ 1 にはNATを割り当てます.さらに,ポートフォワーディングの設定でホストポート2222からゲストポート22へのポートフォワードの設定を追加します (IPの欄は空).また,ホスト-ゲスト間の通信のためにアダプタ 2 にホストオンリーアダプタを割り当てます. - Debianのインストール
普通にインストールします.途中にどのアダプタでインターネットに接続するかを聞かれるので,最初のアダプタを選びます. - IPアドレスの設定など
/etc/network/interfaces を以下のように編集します.# The loopback network interface auto lo iface lo inet loopback # The primary network interface (NAT) auto eth0 allow-hotplug eth0 iface eth0 inet dhcp # The secondary network interface (Host-only) auto eth1 iface eth1 inet static address 192.168.56.102 netmask 255.255.255.0
次にネットワークを再起動します.sudo /etc/init.d/networking restart
- Samba の設定
まず apt で Samba をインストールします.インストール中にWORKGROUPを聞かれるので,WindowsのWORKGROUPと同じものを指定します.sudo apt-get install samba
/etc/samba/smb.conf を編集します.diff はこんなかんじ.--- a/samba/smb.conf +++ b/samba/smb.conf @@ -114,7 +114,7 @@ # This boolean parameter controls whether Samba attempts to sync the Unix # password with the SMB password when the encrypted SMB password in the # passdb is changed. - unix password sync = yes + unix password sync = no # For Unix password sync to work on a Debian GNU/Linux system, the following # parameters must be set (thanks to Ian Kahan < for @@ -239,15 +239,15 @@ # By default, the home directories are exported read-only. Change the # next parameter to 'no' if you want to be able to write to them. - read only = yes + read only = no # File creation mask is set to 0700 for security reasons. If you want to # create files with group=rw permissions, set next parameter to 0775. - create mask = 0700 + create mask = 0644 # Directory creation mask is set to 0700 for security reasons. If you want to # create dirs. with group=rw permissions, set next parameter to 0775. - directory mask = 0700 + directory mask = 0755 # By default, \\server\username shares can be connected to by anyone # with access to the samba server.
Samba のアカウントを作ります.sudo smbpasswd -a nojima
最後に Samba を再起動します.sudo /etc/init.d/samba restart
Windows側のエクスプローラのアドレス欄に\\192.168.56.102
と打ち込んでアクセスできれば成功です. - Windows の hosts ファイルの書き換え
毎回VMのIPアドレスを打ち込むのは面倒なので,hostsに名前を登録しておきます. C:\Windows\System32\drivers\etc\hosts に以下の行を追加します.(debian-vmのところはVMの名前)192.168.56.102 debian-vm
書き換えに管理者権限が必要だったりするので,管理者権限でメモ帳などを実行し,そこから編集するとよいです.
ポートフォワードについて
PuTTYでVMにアクセスする際にはポートフォワードを用いてアクセスする方が便利です.(つまり localhost の 2222 番ポートにアクセスする) 直接VMにアクセスすると,ノートPCをスリープさせた時に接続が切れてしまいますが,何故かポートフォワードを使ってアクセスすると接続が切れません.どうして接続が切れないのかよくわかりませんが,とりあえず便利です.
アプリケーションのメモ
OSの再インストールに備えてリストアップ.
- 1Password
- 7-Zip
- Adobe CS 5.5 Design Standard
- Cytoscape
- Dropbox
- Eclipse
- EmEditor
- Exact Audio Copy
- foobar2000
- Git
- Google Chrome
- Google 日本語入力
- Java
- LimeChat
- Mendeley Desktop
- Microsoft Office Professional 2010
- Microsoft Security Essentials
- Microsoft Visual Studio 2010 Professional
- MinGW
- MySQL Server
- MySQL Tools
- Noah
- NX Client for Windows
- OMake
- Perforce Visual Components
- Player
- PuTTY
- Python
- rsync.net
- Ruby
- Skype
- SumatraPDF
- TortoiseGit
- TortoiseSVN
- Vim
- VLC media player
- VMware Player
- w32tex
- WinCDEmu
- WinSCP
Windowsで快適なLaTeX環境を構築する
Windowsで快適にLaTeXで論文を書くためのメモ.
LaTeXで論文を書いているときは,
テキストエディタで.texを編集する → platexでコンパイル → Adobe Readerでプレビュー → 最初にもどる
という流れで論文を書いていくことになるのですが,いちいちコンパイルしたり,Adobe Readerで開いたりするのは面倒なので,.texを変更したら自動的に変更を検出してコンパイルし自動的にプレビューに反映する環境を構築しました.
使用したソフトは
- w32tex.これがなくては始まらない.abtexinst を使えば何も考えなくてもインストールできます.
- OMake.いわゆるビルドツール.コンパイルの自動化に使用します.
- SumatraPDF.PDFビューワ.PDFを変更すると自動的にリロードしてくれます.
です.
以下では書いているTeXファイルを document.tex とし,BibTeXファイルを refs.bib としています.違う名前を使う場合はこれらの名前を置換してください.また,platexやomakeの存在するディレクトリにはパスが通っているものとします.
まず,document.tex や refs.bib が存在しているディレクトリで omake --install を実行して OMakefile と OMakeroot を生成します.Windows 7だといちいちコマンドプロンプトを開かなくても,エクスプローラーのアドレスバーに「omake --install」と打てばそのディレクトリでomakeを実行することができます.
次に,OMakefileの内容を全て消去して以下のように編集します.
LATEX = platex TETEX2_ENABLED = false LATEXFLAGS = -interaction=nonstopmode BIBTEX = pbibtex DVIPDFM = dvipdfmx DVIPDFMFLAGS = -p a4 TEXDEPS[] = refs.bib LaTeXDocument(document, document) .DEFAULT: document.pdf document.dvi
次に,omake -P --verbose を実行します.このコマンドは,omake を監視モードで起動し,ファイルに変更があった場合は自動的にコンパイルするコマンドです.
次に,document.pdf を SumatraPDF で開いておきます.
後は,document.tex をテキストエディタで編集して保存する度に,omake が自動的にコンパイルを行い,SumatraPDF が自動的にプレビューに反映してくれます.手動でコンパイルするのと比べて,かなり楽にプレビューを見ることができるようになります.デュアルディスプレイだと,片方のディスプレイで PDF を常に表示しておくと,プレビューを見ながら TeX を編集できて,楽しいです.
ただし,TeXでエラーが出てしまうと,platexモードがデバッガモードに入ってしまって自動ビルドが止まってしまうことがあります.こういうときは,コマンドプロンプトの画面で Enter を押すとたいてい動いてくれます.それでもうまくいかないときは omake をいったん終了させてもう一度起動しましょう.ここらへんがもうちょっと何とかなればもっと楽なのですが,解決策がわからない…… -interaction=nonstopmode を LaTeX の引数に与えればエラー時にデバッグモードに入らないようです.
「サマーインターン2011問題 : Preferred Research」について考えてみる
今更ながら,「サマーインターン2011問題 : Preferred Research」について考えたので,ここにメモ.
問題の概要を箇条書きにすると
- 長さ n の文字列 s が与えられる
- s に含まれる文字の中で,出現回数が最も大きい文字を出力せよ
- ただし,出現回数が最大の文字の出現回数は n/2 より大きい
- 計算時間は O(n) でなければならない
- 空間使用量は s を格納するバッファを除いて O(1) でなければならない
- s を格納するバッファは書き換えてよい
解法1
よく考えると,s をソートしたときに n/2 番目に来る要素は,出現回数が最大の文字であることがわかります.「ソートしたときに k 番目に来る要素」というのは,実際にソートをしなくても O(n) で求めることができ,問題の条件を満たします.C++ の標準ライブラリには nth_element という関数が用意されており,これを使うと簡単に「ソートしたときに k 番目に来る要素」を計算できます.
解法2
次のアルゴリズムを考えます.
for (;;) {
添字 i を [0, n) からランダムに選ぶ;
文字 s[i] の出現回数をリニアにカウントする;
if (s[i] の出現回数 > n/2) return s[i];
}
1回の反復で答えが求まる確率は少なくとも1/2あるので,平均計算時間は
(1 + 1/2 + 1/4 + ...) O(n) = O(n)
となり問題の条件を満たします.
[論文紹介] GConnect: A Connectivity Index for Massive Disk-Resident Graphs
授業で論文紹介したので,ここにメモ.
『GConnect: A Connectivity Index for Massive Disk-Resident Graphs』は,巨大なグラフに対してインデックスを作って,辺連結度クエリに高速に答える手法について議論した論文です.以下のような問題を考えます.
巨大なグラフGが与えられる.(例えば,頂点数10万,辺数100万とか)
G内の任意の2点s, tが与えられたとき,sとtの辺連結度を高速に計算せよ.
2頂点の辺連結度というのは,グラフから最小で何本辺を取り除けば,その2頂点を非連結にできるかで定義される量です.
計算時間を気にしなければ,最大 s-t フローを求めるアルゴリズム(Dinic や Goldberg-Tarjan など)で連結度を計算することができます.しかし,これらのアルゴリズムは記憶領域へのランダムアクセスを要求するため,メモリに格納できないサイズのグラフに対しては非常に遅くなり得ます.情報検索への応用を考えると,(s, t)が与えられたときに,数秒で答えを返さなければなりません.そこで,厳密解を求めることを諦め,近似解を求めることにし,事前に巨大なグラフをメモリに収まるサイズまで圧縮しておくことを考えます.
グラフの圧縮は,辺サンプリングに基づいて行います.下図(論文中の図から引用)のように,グラフ内の各辺に対して,一定の確率 f でその辺をサンプルします.そして,サンプルされた辺による連結成分を縮約します.結果として,頂点数と辺数が小さくなったグラフができます.
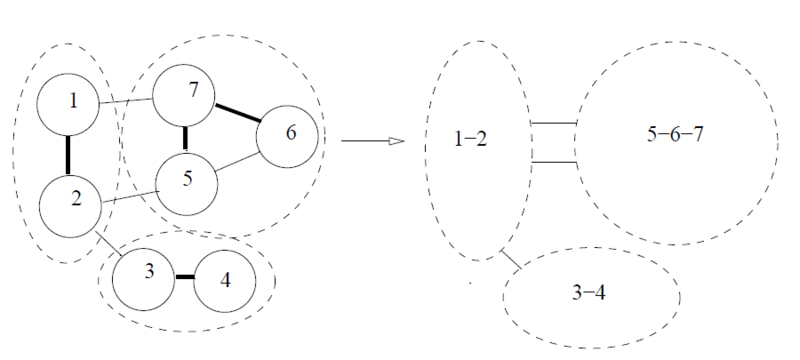
なぜこれで辺連結度の近似ができるのでしょうか?まず,辺連結度というのは,グラフの中の辺が比較的疎な部分で決まりやすいという性質を持っています.さらに,グラフの辺サンプリングは,辺が密な部分は,多くの辺がサンプルされ,一つの頂点に縮約されやすく,また,辺が疎な部分は,余り辺がサンプリングされず,縮約もされにくいという性質を持っています.よって,グラフの辺が疎な部分の構造が辺サンプリングによって保存されやすいため,辺連結度を概ね保存したまま,グラフを圧縮できるというわけです.
頂点対(s, t)に対応する,圧縮されたグラフの頂点対が(s', t')であったとします.ここで,s' ≠ t' とします.真のs-t辺連結度が C であるとすると,辺サンプリングによって正しくs-t辺連結度が求まる確率は少なくとも (1 - f)^C あります.(最小 s-t カットに含まれる辺がいずれも辺サンプリングによって選ばれない確率が (1 - f)^C です)
より高い確率で正しく辺連結度を求めるため,圧縮されたグラフを k 個作成し,それぞれの圧縮されたグラフで辺連結度を計算し,それらの最小値を答えとして返すことにします.(圧縮によって辺連結度が大きくなる場合は存在するが,逆の場合は存在しないので,最小値をとるのが良い)
圧縮されたグラフにおいて,s' = t' になってしまった場合は,辺連結度を計算できません.このような場合に対処するために,論文では,頂点サンプリングを使って圧縮したグラフを導入しています.詳しくは論文を読んでください.
現実のグラフを使った実験結果によると,圧縮によりグラフのサイズを 93% ~ 99% 程度減らすことができ,それによるエラーは6%以下にとどまっています.クエリの計算時間は,ナイーブな場合にくらべて 500倍程度速くなったようです.
[論文紹介] Fast shortest path distance estimation in large networks
とりあえず最近読んだ論文の紹介でも.
Webやソーシャルネットワークなど,巨大なグラフに対して,データマイニングや情報検索を行う際に,頂点間の最短距離を計算するという処理は,しばしば必要されますが,この規模のグラフに対して,BFSやDijkstra法を直接行うと時間がかかりすぎるという問題があります.『Fast shortest path distance estimation in large networks』は,頂点の小さなサブセットに対して,予め最短距離を求めておくことで,最短距離クエリに対して高速に答えを近似する手法について議論した論文です.アルゴリズムは大体以下のようになります.
- 上手く頂点のサブセットを選ぶ.ここで選ばれた頂点をランドマークと呼ぶことにする.
- グラフ内の任意の点vと,任意のランドマークuに対して,vからuへの最短距離を記録しておく.
- sからtへの最短距離クエリが与えられたとき,全てのランドマークuに対して,
(sからuへの最短距離) + (tからuへの最短距離)
を2で記録した値から計算し,その最小値を最短距離の近似値として返す.
このアルゴリズムでは,1のランドマークの選び方によって,近似の良さが変化します.(sからuへの最短距離) + (tからuへの最短距離) が,(sからtへの最短距離) に一致する必要十分条件は,uがsからtへの最短経路上にあることなので,ランドマークは,できるだけ最短経路に多く含まれている頂点を選べば良さそうだという直観を得ることができます.しかし,最良のランドマークを選ぶ問題はNP困難であることが証明できるので,ランドマークはヒューリスティックに選ぶことになります.論文では,ランドマークの選択に使うヒューリスティックをいくつか提案し,それらを比較していました.平均的に最も良い結果を与えるとされたヒューリスティックは closeness centrality の考え方に基づくものでした.
頂点vの closeness centrality は,その頂点からグラフ内の全ての頂点への最短距離の平均で定義されます.直感的に,小さい closeness centrality を持つ頂点は,多くの最短経路に含まれていると考えられるので,よいランドマークの候補になります.closeness centrality は,真面目に全頂点への最短距離を求めなくても,頂点のサンプリングをすることで精度良く近似できるらしいです.
実験では,closeness centrality が小さい順にランドマークを選んだ場合,ランダムに選んだ場合と比べて,同じ近似精度を1/250のランドマーク数で達成しています.辺数が7000万以上あるグラフに対して,数十個のランドマークで,真の最短距離との相対誤差が10%以下に抑えられており,結構上手く近似できているようです.